Padmé: Efficiently Hiding File Sizes
Date: 08/01/2020 - go back home

Padmé is a padding algorithm notably used in Padded Uniform Random Blobs (PURBs).
It hides efficiently the true size of files or network messages. Padmé is designed to work even when objects have very different sizes, and notably outperforms trivial padding approaches. No assumption is made on the underlying size distribution.
It is practical. Its overhead is at most +12%, and this number decreases with increasing object size: at most +6% for a 1Mb object, at most +3% for a 1Gb object.
Use Padmé freely in your projects: see the implementation below (New BSD license).
Read the
paper (section 4)
View the slides (sarting at slide 37)
Padmé is a joint work between L. Barman*, K. Nikitin*, W. Lueks, B. Ford, and J-P. Hubaux.
✨ Update: Padmé is used in Apple's iMessage and Meta's Messages !
Sizes reveal a lot of information
Consider a user downloading a movie from a service like the Apple Store. Their connection is secured with TLS and should be private.
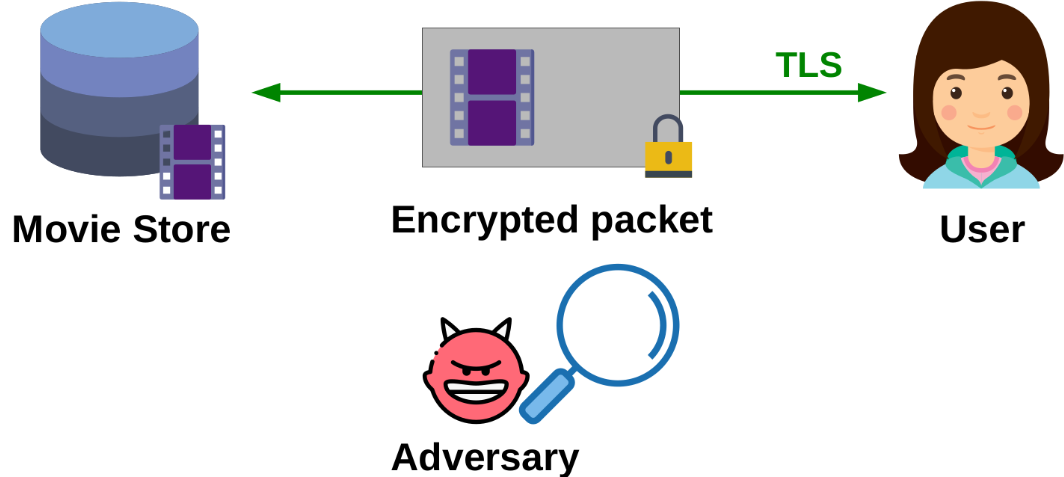
Even with robust encryption ensuring confidentiality, an eavesdropper (e.g., an ISP) can often infer the content based on metadata. In this case, the source/destination reveals the connection to the Apple Store; then, the download size is metadata not protected by encryption. With this information, if movie sizes are distinct enough, the attacker can identify the movie without breaking the encryption.
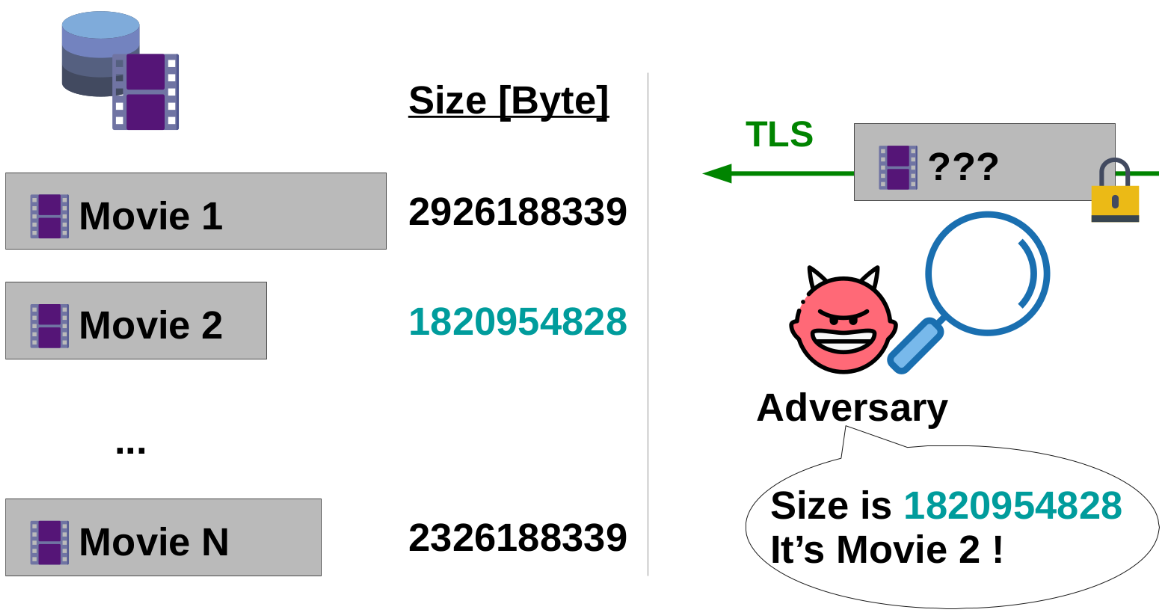
Researchers have consistently demonstrated that metadata, such as total transfer size, can reveal encrypted content [1,2,3,4].
A common mitigation is to pad (artificially extend) files to reduce size uniqueness. This introduces overhead, and the critical question is how much padding is necessary. Let's see below how Padmé pads files with a better overhead than naïve approaches.
Naïve approaches
Constant block-size
The simplest approach is to pad to a constant block size: for example, pad to the next multiple of B=512 bytes. This is the approach taken by many tools (e.g., all Tor cells are padded to 512 bytes) due to its simplicity. However, for padding objects which might have very different sizes, the approach is clearly suboptimal. In fact, in this case, there's no good value for the block size B! Take B=1 MB for instance; small network messages would incur a large overhead, and at the same time, it would add very little confusion to large files.
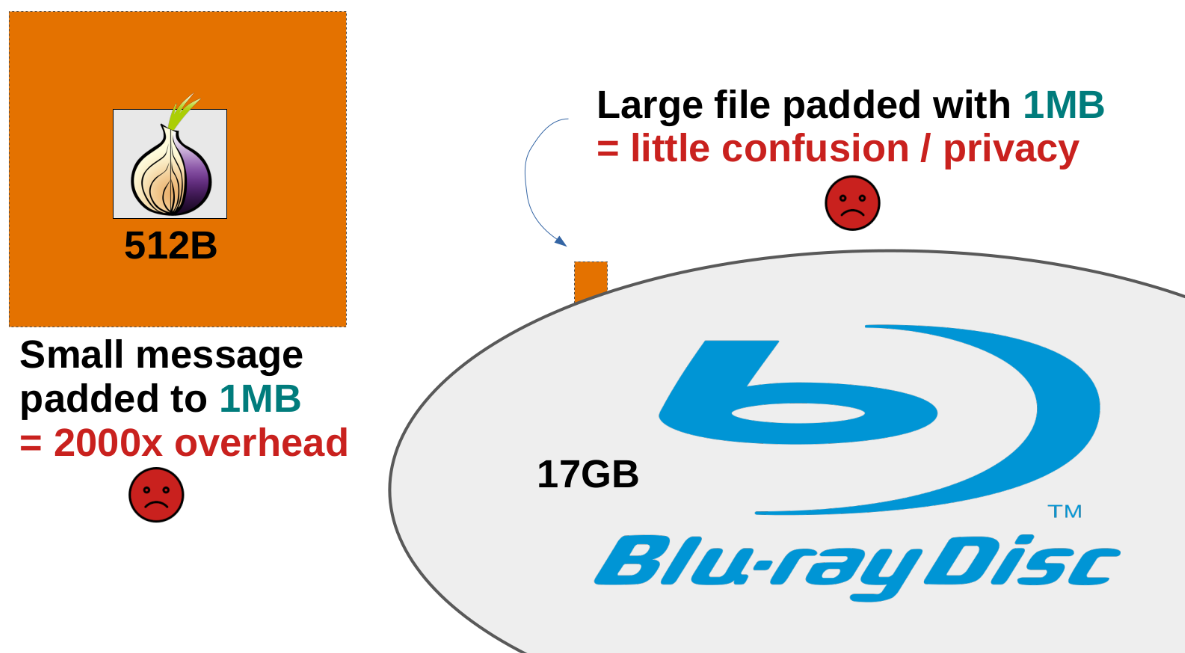
It seems clear that we want the padding to somehow be relative to the size of the padded object.
Next Power of Two
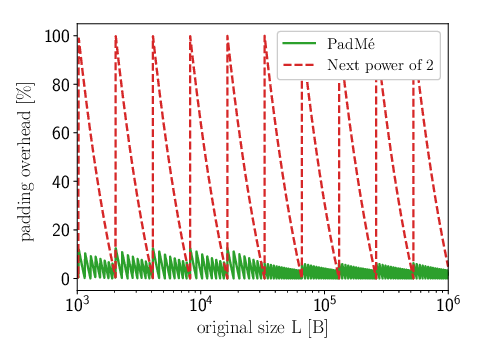
Another approach is padding to the next power of 2: this way, small objects have small overhead (e.g., a 900 bytes network message is padded into 1024 bytes), and large objects have a relatively larger overhead (e.g., a 15 GB movie is padded into 16 GB). This looks better already, and in fact, we can show that the asymptotic leakage (that is, the information revealed to the adversary) is much lower : for M being the biggest plaintext size considered, the leakage is of O(log(log(M)) for the Next Power of Two, versus O(log(M)) for padding to the constant block size.
However, this approach is often impractical due to significant overhead: a 16.1 GB movie is padded into 32 GB (nearly +100% overhead).
Padmé
Padmé gets best of both world: its leakage is O(log(log(M)) like Next Power of Two, which is much lower than the trivial approach; additionally, its max overhead is +12% and decreasing (max +6% for a 1Mb object, max +3% for a 1Gb object).
Leakage, in especially in asymptotic terms, is a bit difficult (for me) to grasp. Let's analyze concretly what "a leakage of O(log(log(M))" means in practice. Let's analyze the "size privacy" of Padmé in practice; in this experiment, we collect 57'000 object sizes from Ubuntu packages and show how unique the sizes are:
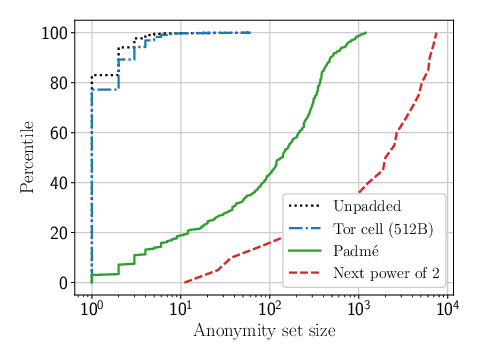
In particular, we see than more than 80% of unpadded objects have a unique size, and when padded with the naïve constant-block-size approach (like a Tor cell), still more than 75% of the objects are uniquely identifiable only with their size. If you were to download one of these files over TLS, an adversary would trivially know the contents with certitude in 75% of the cases!
Then, we see that Next Power of Two is great at "grouping" padded files together: less than 40% of the files have an anonymity set of 1000 or less (the same padded size as 1000 other files or less). Again, this approach is impractical due to having a large overhead.
The most interesting difference is between the poorly-protected constant-block-size approach and Padmé: for a cost of (at most) +12% overhead, the anonymity sets are drastically larger: less than 20% of the files have an "anonymity set" of 10 or less. In particular, no padded file has a unique length anymore, which would make it easily identifiable by the adversary.
How does Padmé work ?
The privacy/overhead trade-off is fundamental, and Padmé cannot improve one without degrading the other, like all padding schemes. However, Padmé is carefully designed so its privacy/overhead trade-off depends on the object size in a nice way. Intuitively, we want small files to have (reasonably) large overhead for privacy, and large file to have "just enough" padding in percentage, since the absolute overhead is very costly for large files.
Padmé can be implemented in just a few lines of code; please refer to the paper (or the presentation) for the theoretical analysis.
Scope & Limitations
Padmé is a generic padding scheme which performs well when the distribution of object sizes is unknown. Our intent is "if you don't know what to apply, Padmé is a good default". If the distribution of objects is known, it's very likely that a specially-crafted padding function would perform better.
Implementation
Python3 implementation. Yes, it's that short:
import math
from math import floor
def log(x): # we use log in base 2
return math.log(x, 2)
def padme(L):
"""
Pads the length L using the Padmé algorithm
Args:
L (int): unpadded object length
Returns:
int: the padded object length
"""
E = floor(log(L))
S = floor(log(E))+1
lastBits = E-S # we want those bits to be 0
bitMask = (2 ** lastBits - 1) # create a bitmask of 1's
return (L + bitMask) & ~bitMask # round up if necessary
References :
- [1] Schuster, Roei, Vitaly Shmatikov, and Eran Tromer. Beauty and the burst: Remote identification of encrypted video streams. USENIX Security 17
- [2] George Danezis. Traffic Analysis of the HTTP Protocol over TLS.
- [3] Dyer, Kevin P., et al. Peek-a-boo, i still see you: Why efficient traffic analysis countermeasures fail. IEEE S&P 12
- [4] Reed, Andrew, and Michael Kranch. Identifying HTTPS-protected Netflix videos in real-time. ACM on Conference on Data and Application Security and Privacy 2017
Icons made by Flaticon, authors: Smashicons, Freepik, Vitaly Gorbachev.